标题所说的诊断预测是指ICD-10、ICD-9等国际疾病分类编码预测,也就是疾病的细粒度编码分类预测。为什么说是细粒度呢?因为我们日常听说的疾病如“糖尿病”、”高血压”、“肝硬化”这一粒度的疾病,常见的就几百上千种,而ICD-10编码有2万多个,像“糖尿病”一共覆盖了108个ICD-10诊断,粒度够细吧。
目前使用较多的ICD-10由5个等级组成,分别为“章”、“节”、“类目”、“亚目”和最细粒度的6位编码,粒度由粗到细,前一级为后一级的父节点,整个编码体系为树结构,编码由字母和数字组成,最细粒度包含2万多个6位编码。所以,这是个超超级多分类问题。
诊断预测的输入数据通常是电子病历或者病案首页数据,电子病历数据详尽,但实在是有点杂乱,病案首页数据高结构化,但数据信息量太小了。无论是病历数据还是病案首页数据,对于住院患者来说,一份数据通常包含多个诊断编码,或许是1个,或者2个,也可能15个,因此,我们面临的又是多标签问题。
这个超超级多分类多标签预测,由于各种原因,目前效果貌似很不理想,基本f1值都没超过0.6(此值不包含某个单一科室数据的预测)。
最近正研究这个,论文看了一些,下面总结一下最近看的论文吧。
1. 《基于电子病历的临床医疗大数据挖掘流程与方法》
时间:2017年
目标:针对10项疾病的预测
方法:A. seq2seq做自编码器,取中间编码C做每个病人的病历做向量化;B. 采用SVM、K-Means、GMM做分类算法。
结果:统计每一项疾病的AUC,最高AUC为0.84,大部分在0.7-0.8之间,最低为0.52(f值就不用说了)。
备注:预测疾病,而不是ICD-10编码,疾病对应到ICD-10的级别基本都比6位粗。
Google上搜索“ICD-10 诊断编码器”,搜索出来的都是嵌入到病历系统的编码器、编码转换器等产品,没有基于电子病历自动编码的产品。通过“EMR ICD-10 diagnosis prediction”搜出来的论文较少,汇总了一下,大概情况如下:
2. Google暴力计算神作——《Scalable and accurate deep learning for electronic health records》
时间:2018年初
目标:预测死亡率、住院天数、出院诊断编码、再入院率。
方法:将病历映射成临床路径时序化数据,然后用了三种看着并没有什么联系的算法(LSTM、前馈网络、决策树)预测以上4个目标。
结果:

备注:A. Jeff Dean 带领AI界、医学界大牛,在2018年,用以上三个算法做出来的工作;B. 数据来自两家医院,共10多万病人;C. 计算设备时间开销积为20万GPU时。D. 由于对数据的前期处理仅做了时序化映射,文本的个性特点依然保留,做出来的模型对其他数据泛化能力不一定强。
综合以上3点,总结起来就是大牛们在新领域的豪华暴力尝试,这种方式对于我等小民,着实不太实用。
3. 《EMR Coding with Semi-Parametric Multi-Head Matching Networks》
时间:2018年中
目标:基于电子病历做ICD诊断预测
方法:将手上的电子病历分为大小两份,小的一份作为“支持集”,个人理解,相当于编码器的参考集合,大的一份用于训练。训练目标为预测诊断编码,同时用类KNN的方式找到“支持集合”中与输入病历最接近的“参考病历”,计算各预测诊断和参考病历各诊断的相似度。
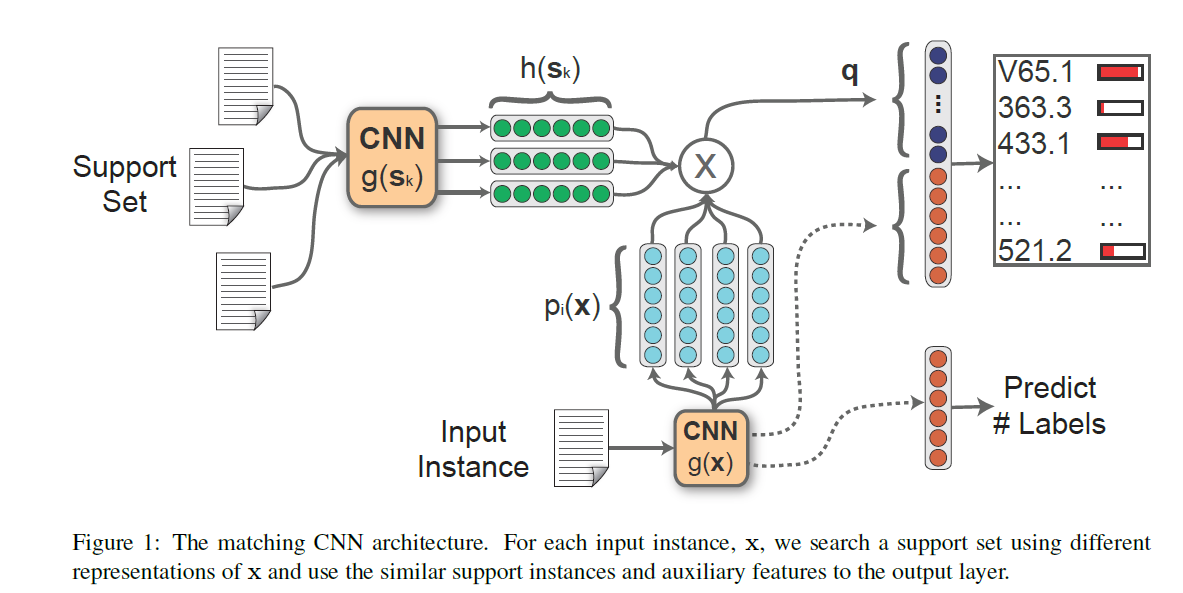
结果:
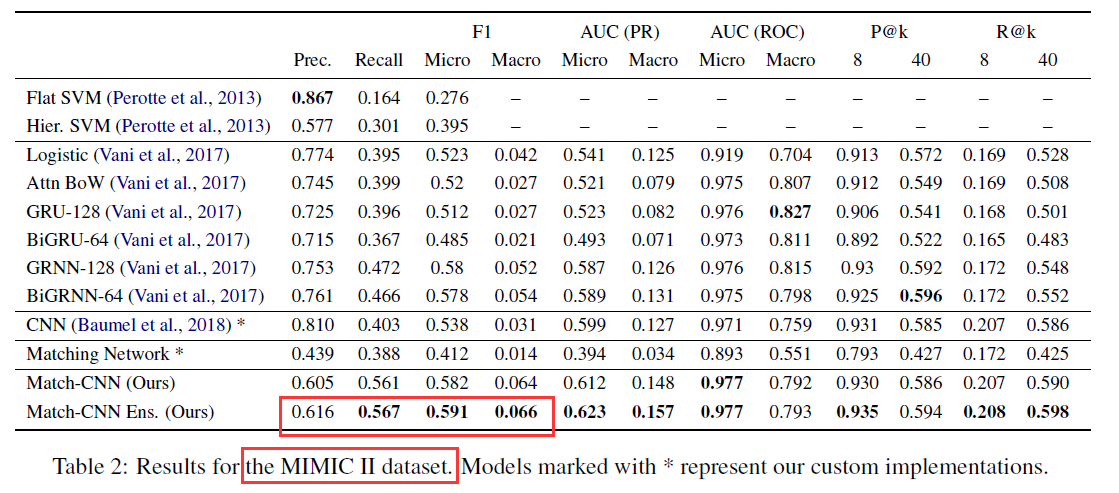
备注:最近刚接触“匹配网络”这个字眼,还不熟,也不知道此匹配网络是否为其他论文提到的匹配网络,有必要了解一下。
4. 《Unsupervised Extraction of Diagnosis Codes from EMRs Using Knowledge-Based and Extractive Text Summarization Techniques》
时间:2014年
目标:通过电子病历自动做ICD-10编码
方法:基于知识图谱和文本总结技术,从电子病历中提取诊断编码。这是早期无监督预测诊断的代表性论文,基于规则,从杂论的病历文本中抽取诊断短文本,然后匹配。
备注:这篇论文只能下简洁部分,没有找到完整论文下载。
5. 《KAME: Knowledge-based Attention Model for Diagnosis Prediction in Healthcare》
时间:2018年10月
目标:基于疾病知识图谱和过往电子病历数据预测下一次入院可能出现的诊断。
方法:通过GRAM模型做疾病知识图谱嵌入训练,通过预训练的向量模型来获取病历个实体向量,用RNN提取特征做预测,并用知识图谱做注意力机制,监督RNN后的分类预测。
结果:
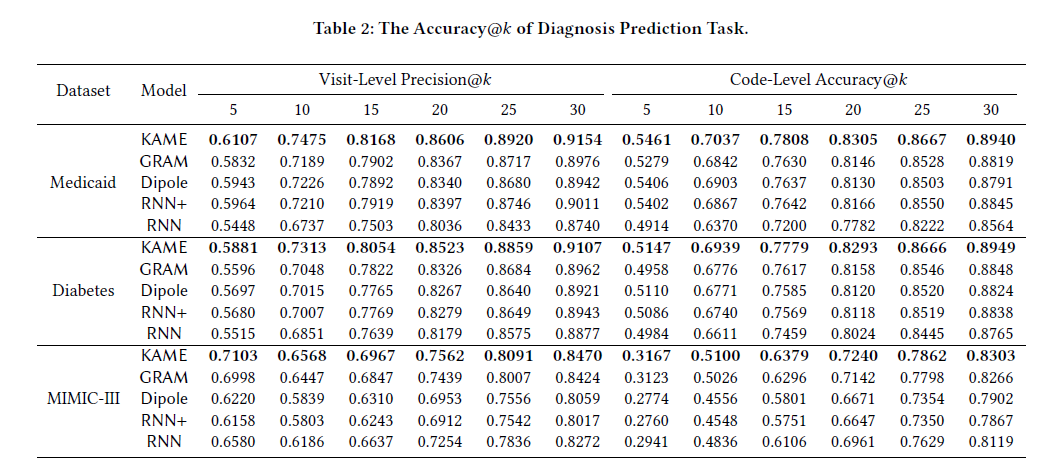
备注:和其他论文研究的方向不同,其他几篇是基于病历数据预测此次的诊断编码,属于事后预测,服务于医院病案科,或者治疗科室的医生,而不是患者;这一篇论文根据病人以往的诊断编码历史数据预测下一次可能的诊断,属于事前预测,更倾向于服务患者。